|
I am a third-year Ph.D. student in the Electrical and Computer Engineering department at University of Washington, Seattle. Currently, I am a member of NeuroAI Lab advised by Prof. Eli Shlizerman. My current research interest is multi-modal research for spatial reasoning in 3D scenes, as well as the related applications on multi-modal LLMs, XR devices and robotics. I am grateful to be supported by the Google PhD Fellowship. Before that, I received my Bachelor’s degree in Computer Science and Technology from the Experimental Program for Exemplary Engineers at Huazhong University of Science and Technology (HUST), China, in 2020. I am also lucky to work with Prof. Chang Wen Chen and Prof. Junsong Yuan, human detection and segmentation in Bytedance AI Lab, human-object interaction (HOI) with Prof. Si Liu, multiple-object tracking (MOT) with Prof. Jenq-Neng Hwang in IPL lab, and 3D photo-realistic digital human rendering with Prof. Shuicheng Yan and Prof. Jiashi Feng in Sea AI Lab, and wonderful multi-modality 3D research in Meta Reality Labs. I'm open to research collaboration. Please email me (lasiafly [at] uw.edu) if you are interested to explore more on multi-modal for spatial reasoning in 3D together! |

|
|
|
Omni-Modal Foundation Models for Realistic 4D Dynamic Scenes: |
|
Mingfei Chen, Zijun Cui, Ruoke Zhang, Hyeonggon Ryu, Eli Shlizerman Arxiv, 2026 arxiv / video / webpage SceneBind represents realistic scenes as semantic-spatial entities, jointly modeling what is present and where it is across vision, binaural audio, and language. |
Multi-Modal LLM for 3D Spatial Reasoning: |
|
Mingfei Chen, Yifan Wang, Zhengqin Li, Homanga Bharadhwaj, Yujin Chen, Chuan Qin, Ziyi Kou, Yuan Tian, Eric Whitmire, Rajinder Sodhi, Hrvoje Benko, Eli Shlizerman, Yue Liu European Conference on Computer Vision (ECCV), 2026 arxiv / video / webpage / code / bibtex We present EgoMAN, a unified framework for interaction-structured 3D hand trajectory prediction that models hand motion as stage-aware interactions between the hand and surrounding objects. |
|
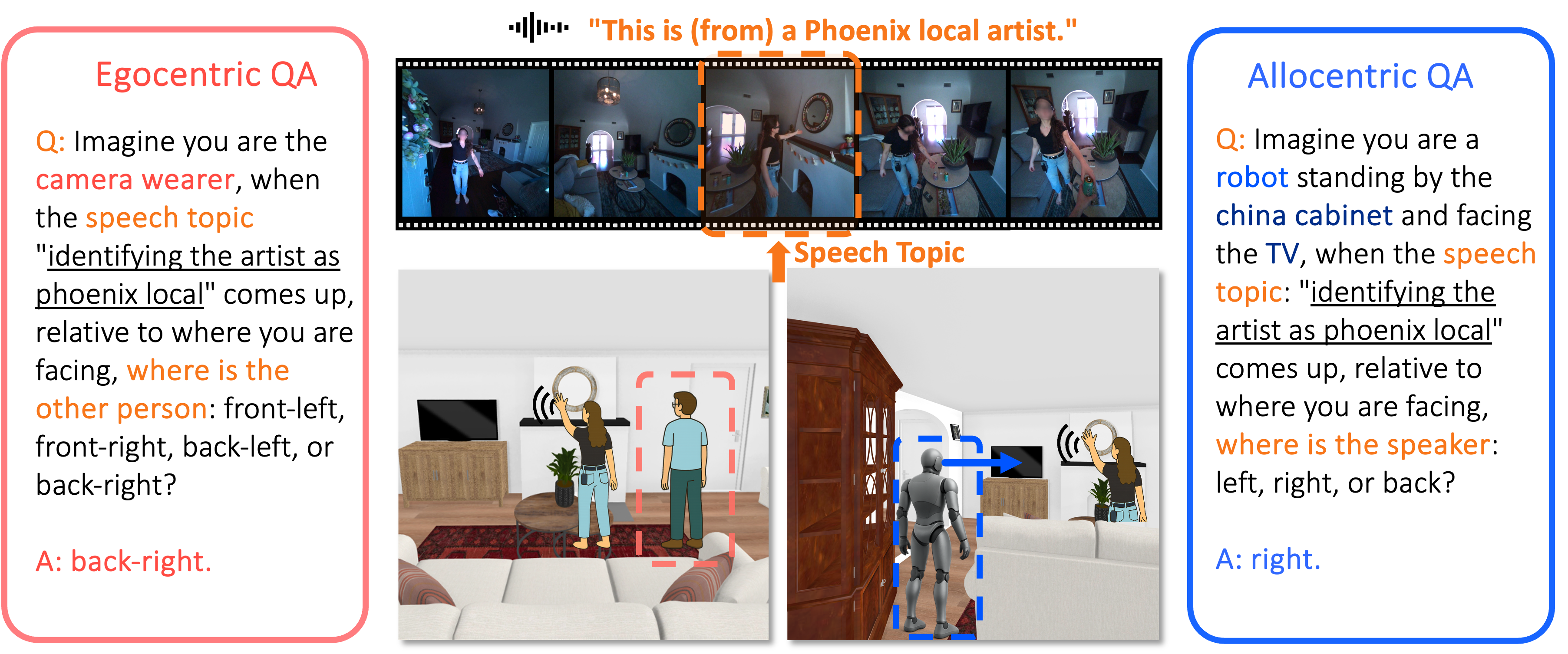
Mingfei Chen*, Zijun Cui*, Xiulong Liu*, Jinlin Xiang, Caleb Zheng, Jingyuan Li, Eli Shlizerman Neural Information Processing Systems (NeurIPS), 2025 (Oral) arxiv / webpage / demo / code / dataset / bibtex We introduce SAVVY-Bench, the first benchmark for 3D spatial reasoning in dynamic audio-visual scenes. We also propose SAVVY, a novel training-free pipeline integrating egocentric spatial tracks and dynamic global maps, which significantly enhances AV-LLM performance for improved audio-visual spatial awareness in such environments. |
Spatial Audio-Visual for 3D Scenes: |
|
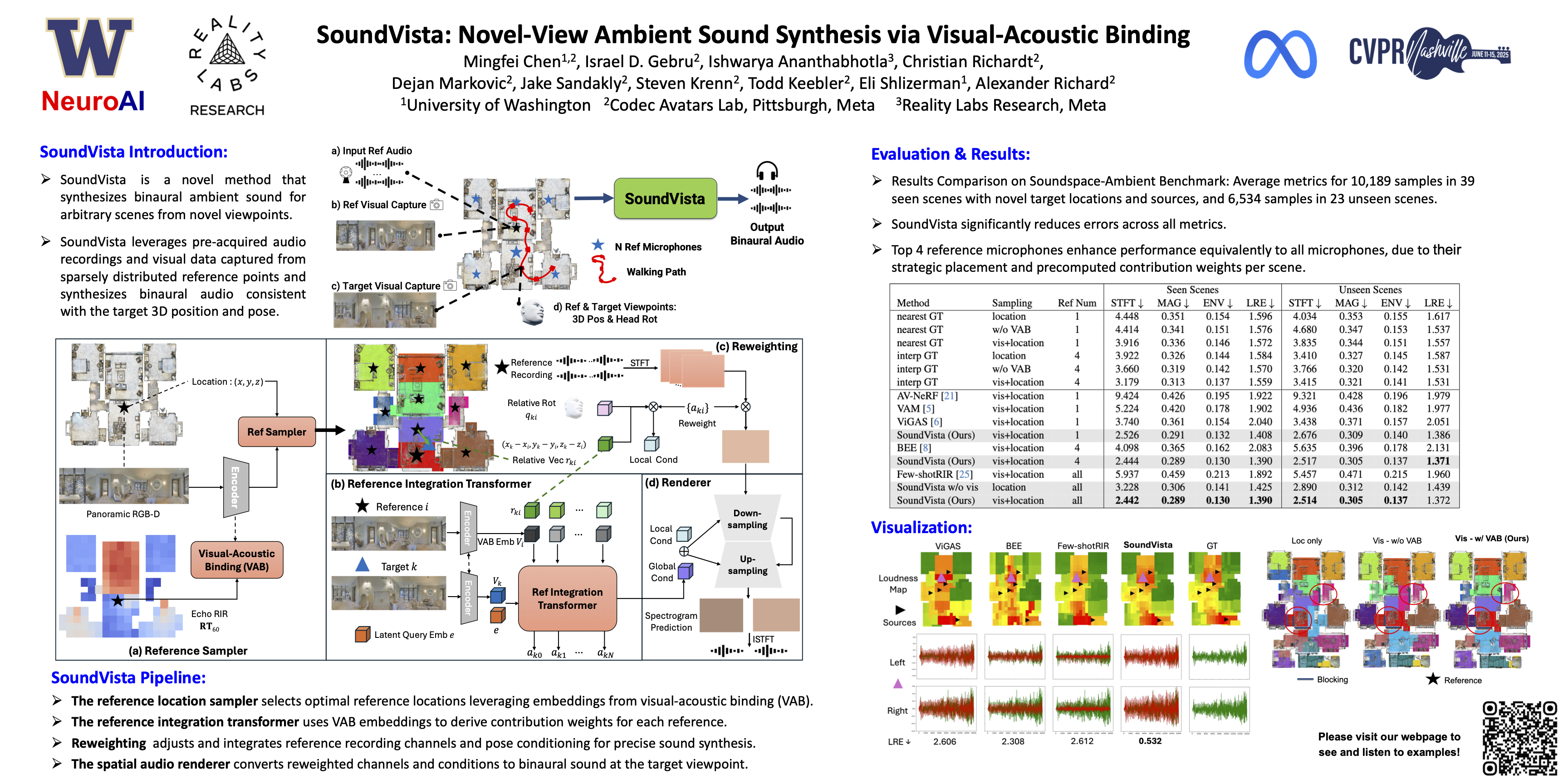
Mingfei Chen, Israel D. Gebru, Ishwarya Ananthabhotla, Christian Richardt, Dejan Markovic, Steven Krenn, Todd Keebler, Jacob Sandakly, Eli Shlizerman, Alexander Richard Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight) paper / webpage / poster / video / code / bibtex We introduce SoundVista: a neural network pipeline to generate the ambient sound of arbitrary scene at novel viewpoints, without requiring any constraint or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. |
|
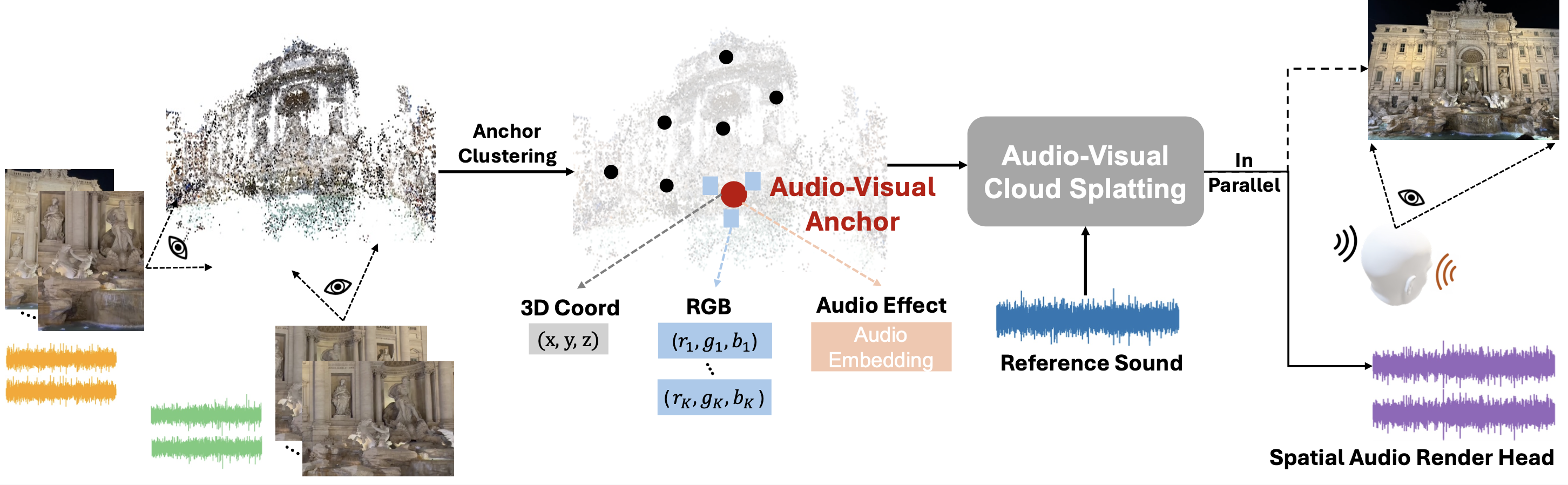
Mingfei Chen, Eli Shlizerman Neural Information Processing Systems (NeurIPS), 2024 paper / bibtex / webpage / poster / video / code AV-Cloud is an audio rendering framework synchronous with the visual perspective. Given video collections, it constructs Audio-Visual Anchors for scene representation and transforms monaural reference sound into spatial audio. |
|
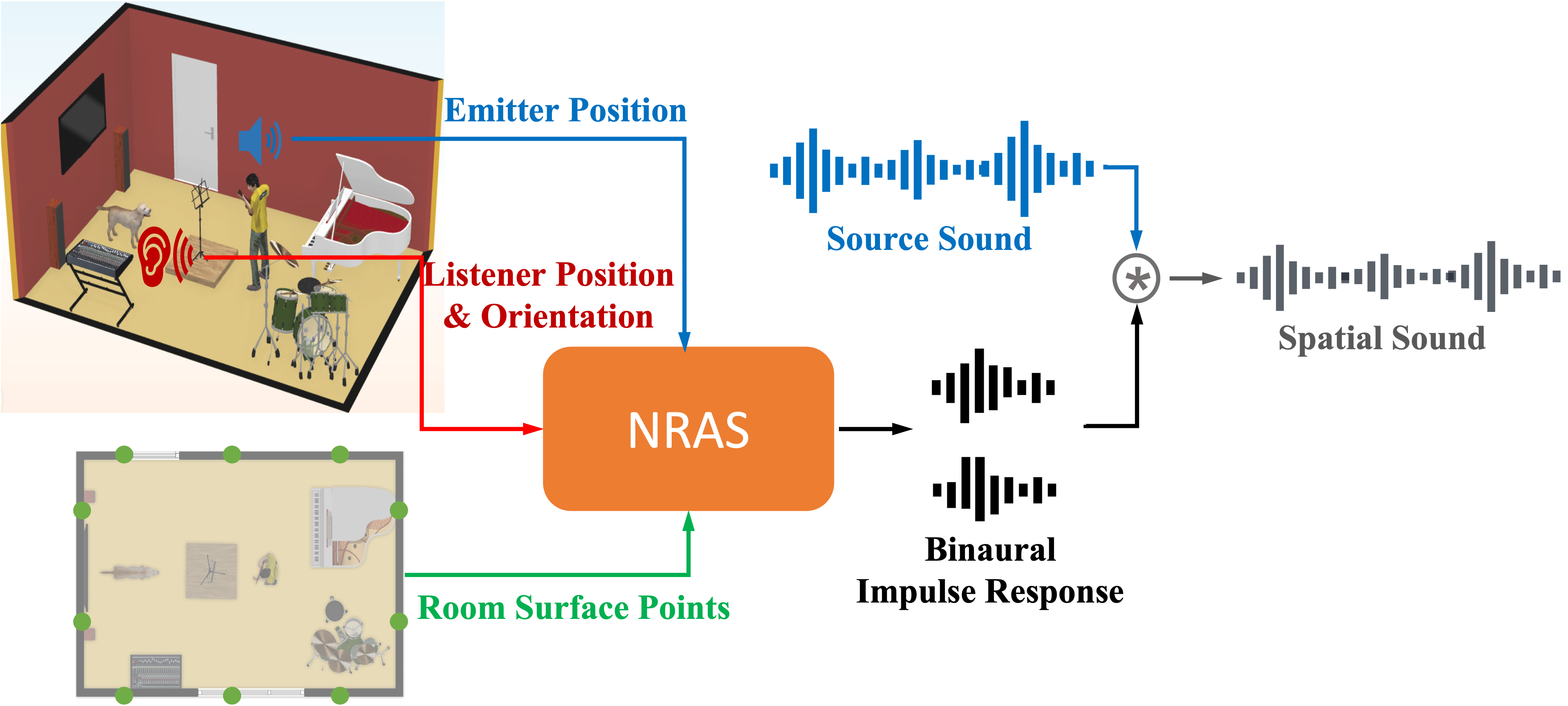
Kun Su*, Mingfei Chen*, Eli Shlizerman Neural Information Processing Systems (NeurIPS), 2022 paper / bibtex / poster / video / supplementary with code We propose an Implicit Neural Representation for Audio Scenes, INRAS, for efficient representation of spatial audio fields with high fidelity. |
{kind=link}
3D Vision: |
|
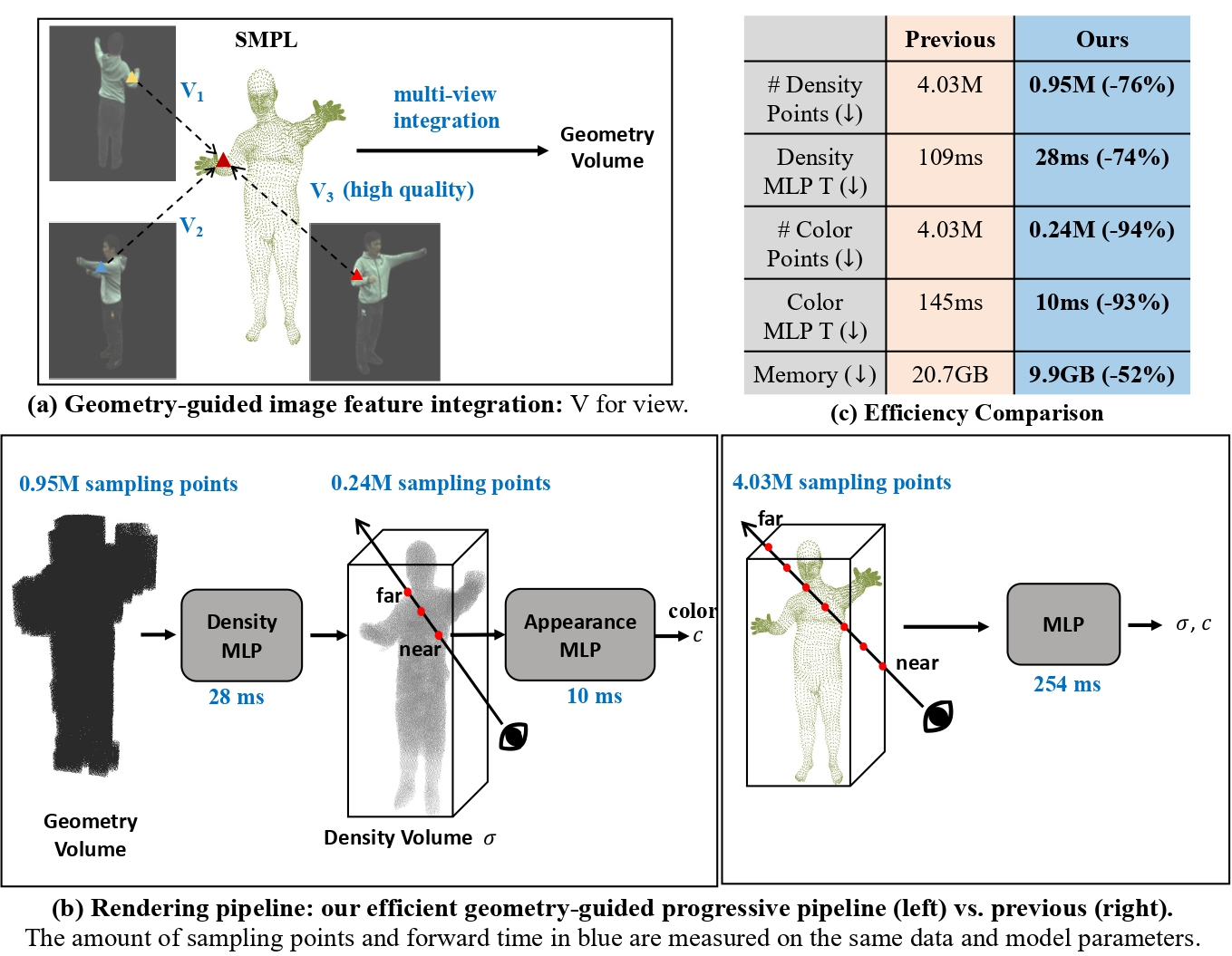
Mingfei Chen, Jianfeng Zhang, Xiangyu Xu, Lijuan Liu, Yujun Cai, Jiashi Feng, Shuicheng Yan European Conference on Computer Vision (ECCV), 2022 paper / bibtex / poster / video / code We develop a geometry-guided generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. |
Visual Relationship: |
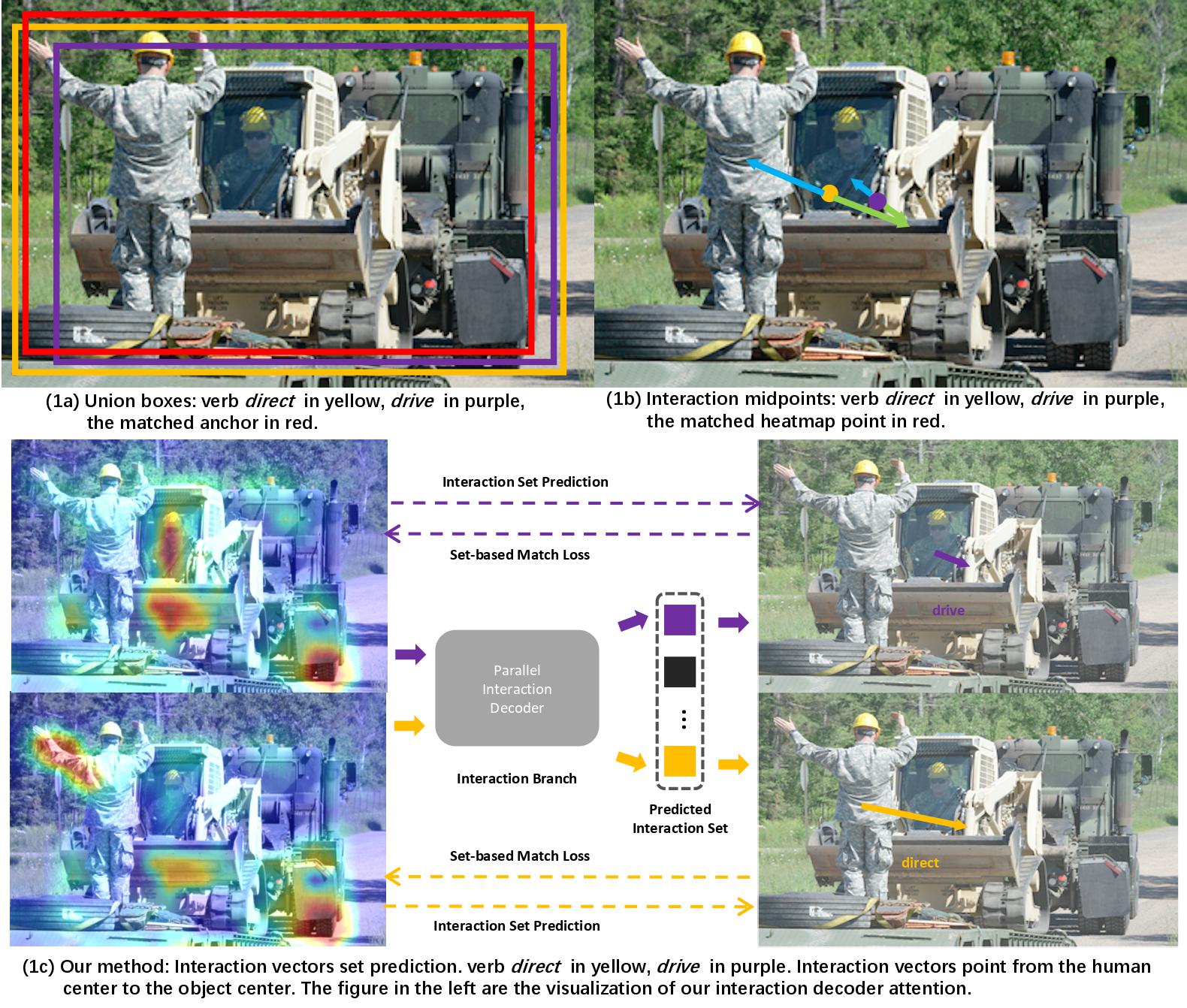
|
Mingfei Chen*, Yue Liao*, Si Liu, Zhiyuan Chen, Fei Wang, Chen Qian Computer Vision and Pattern Recognition (CVPR), 2021 paper / bibtex / poster / code We reformulate HOI detection as an adaptive set prediction problem, with this novel formulation, we propose an Adaptive Set-based one-stage framework (AS-Net) with parallel instances and interaction branches. |
|
|
|
|
|
|